课题组第四周学习
ZeRO-Offload方法
提出背景
对大模型训练来说,GPU显存对参数规模巨大的网络来说是一个瓶颈,然而CPU内存可以做到TB级别,因此可以考虑将一部分参数放在CPU上,而将需要频繁访问的参数放在GPU上,这样可以减少GPU显存的压力,提高训练速度。ZeRO-Offload提出了一种没有数据冗余的优化方法,可以将模型参数分布在CPU和GPU上,而且可以在CPU和GPU之间进行无缝的迁移。
大模型传统方法
针对大模型需要的内存过大的问题,传统分为两种方法:
- 模型分割:将模型分割成多个部分,每个部分在GPU上训练,然后将结果传递给下一个部分,
- 流水线并行:将训练过程分为不同层,每个层分给不同的GPU,然后将结果传递给下一个GPU
增益来源
根据计算流程,CPU的计算量相比于GPU的$O(MB)$,只有$O(M)$,其中M是模型大小,B是批次大小。
这个过程中,ZeRO-Offload将前向与后向传播分配给了GPU,而标准化计算和权重更新等对模型大小有直接联系的计算则分配给了CPU。
在数据吞吐方面,cpu与gpu之间仅存在fp16数据的传输,相比与其他方法(例如L2L)有大幅度减少
在并行方面,随着计算节点的增加,CPU的计算资源会随着节点数量增加而增加
CPU计算通过提高并行性增加了效率
对CPU作为计算瓶颈的解决方法
对CPU计算的优化
- 向量运算SIMD
- 循环展开
- 多核并行
- 减少缓存抖动
延迟参数更新
将参数更新延迟,重叠CPU与GPU计算。也就是说,在某一轮计算之后,此后每次gpu使用的优化器参数都是上一轮计算的结果,而不是这一轮计算的结果。,因此可以让cpu计算时间和gpu计算时间重叠。提高流水线负载率。优化方法
ZeRO-Offload 同时利用CPU内存计算能力来优化。基于ZeRO优化方法,但是不是像原本多个GPU并行计算,并且通过联系收集器来进行并行。而是把这个通讯过程转化为与CPU的联系,相当于原本多个GPU同时做的工作,让单个GPU进行,每个阶段只进行原先一个GPU进行的工作,同时把其他GPU本应进行的计算状态经由内存进行存储。ZeRO的工作
ZeRO,在ZeRO-Offload中使用ZeRO-2阶段,这个阶段你主要是分割模型状态和梯度。在ZeRO-2中,每个GPU都存储着所有参数,但是每轮训练只更新其中不包含的部分。
这个过程如下:
- 每个GPU进行前馈,计算不同批次的损失。
- 每个cpu进行反向传播,并且对每个有梯度的GPU使用减少梯度的算子进行平均。
- 反向传播结束后,GPU使用其对应的梯度平均值对其部分参数和优化器状态进行更新。
- 进行一次全收集,接收其他GPU计算的参数更新。
ZeRO-Offload的工作
ZeRO-Offload将训练修改为数据流图,主要优势:使得CPU计算量减少了几个数量级。保证CPU与GPU通讯最小化。最大限度节省内存。
计算流图
计算流图是一种图形化的表示,用于表示计算过程中的数据流动。在计算流图中,节点表示计算,边表示数据流动。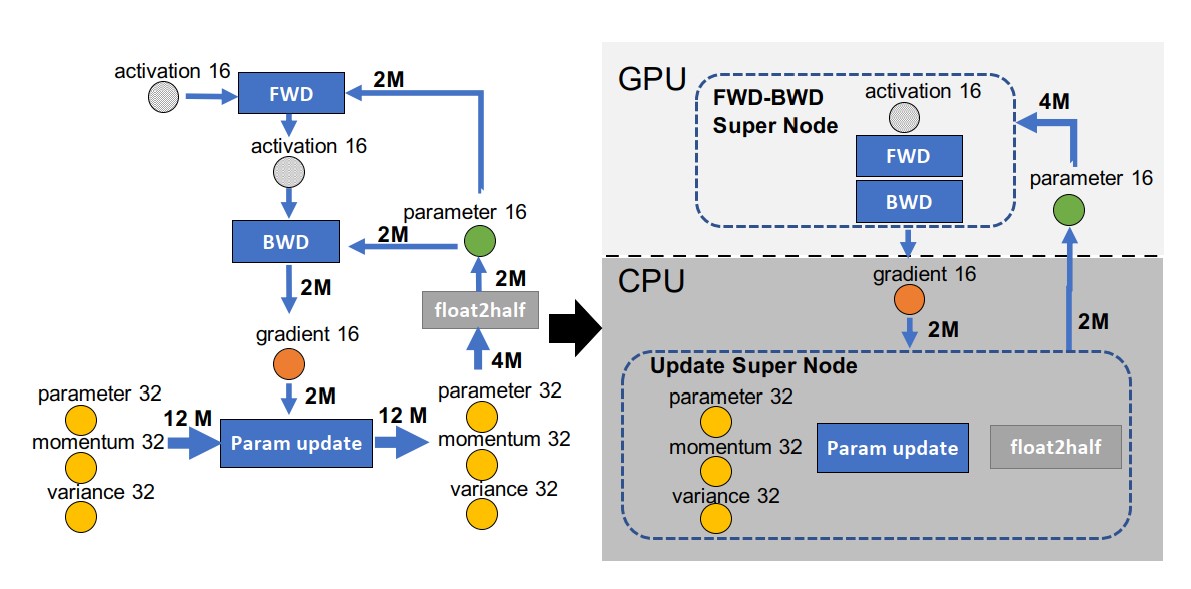
减少CPU计算
ZeRO-Offload将前向与后向传播分配给了GPU,而标准化计算和权重更新等对模型大小有直接联系的计算则分配给了CPU。
减少CPU与GPU通讯
创建fp32区:为了避免fp32数据在pcie总线传输,需要将所有fp32数据放在一个设备上进行处理
p16分配:将fp16必须放在前馈与反向传播共同节点的位置,因为这两个节点之间的通信是较大的。
因此,ZeRO-Offload将fp16分配给GPU,而将fp32分配给CPU。
减少内存
将反向传播后得到的梯度,以及更新梯度所需要的计算和存储空间,写遭到CPU上,可以节省最多的显存使用。
优势
扩展性强
对于任何模型,其优化算法的优化参数对于ZeRO-Offload来说并不关键,其只是需要把fp32的计算内容单独放在CPU中。
支持并行
对多个GPU而言。ZeRO-Offload基于ZeRO-2,因此可以将分区的参数分配给多个GPU。
模型并行
ZeRO-Offload还可以用模型并行来实现更好的并行性。通过给cpu卸载梯度、优化器状态和优化器计算来和模型并行计算相适应。在这个情况下,首先,借由更难耗尽内存,可以使用更大的批次大小。其次,可以使用更多的GPU来进行模型并行计算。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!