课题组第一周学习
理论学习
反向传播算法
反向传播是一种基于有监督学习,用于根据误差和损失函数调整网络权重的算法。反向传播算法的核心思想是通过链式法则计算损失函数对于每个权重的梯度,然后使用梯度下降法更新权重。
过程:
- 首先通过正向传播,根据输入数据得到一个网络的激励
- 根据得到的激励与目标值计算损失函数
- 根据损失函数,从输出层开始,依次沿着计算图反向计算每个权重的梯度
- 根据得到的梯度调整权重
[1] 深度学习入门: 基于Python的理论与实现[M]. 人民邮电出版社, 2018.(p.121,161)前馈
前馈神经网络是一种最简单的神经网络,它的每个神经元都是前一层神经元的输出。前馈神经网络的每个神经元都是前一层神经元的输出,因此它的输出不会反馈到输入层,这种网络结构也被称为前馈神经网络。
卷积神经网络
卷积
卷积(convolution)是一种数学运算,主要应用于信号处理中对系统响应的计算。卷积运算可以将某个冲激响应针对任意输入进行计算,得到对应的响应结果。卷积运算的公式如下:
$$
y(t) = \int_{-\infty}^{\infty} x(a)h(t-a)da
$$
其中,$x(t)$为输入信号,$h(t)$为系统响应,$y(t)$为输出信号。
二维离散卷积
对于图像处理来说,卷积需要用到二维矩阵的滑动窗口来进行卷积运算。二维离散卷积的公式如下:
$$
y(i,j) = \sum_{m=-\infty}^{\infty}\sum_{n=-\infty}^{\infty}x(m,n)h(i-m,j-n)
$$
其中,$x(m,n)$为输入图像,$h(i,j)$为卷积核,$y(i,j)$为输出图像。
卷积神经网络
卷积神经网络(CNN)中,增加了卷积层和池化层。其可以从原本多维度的数据中提取欧氏距离较近的单元之间蕴含的信息。
卷积层
在卷积层中,当输入数据是图像时,卷积层会以三维数据形式接收数据,并以三维数据形式传输到下一层,输入输出数据称为特征图(feature map)。其中,卷积层的输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。
CNN的处理流
针对一个图像,有三维的信息(长、宽、通道),同样,对这个图像进行处理的卷积核也是三维的。但是最终卷积得到的输出结果是二维的(每个通道卷积的结果加在一起)。在CNN中,针对多个卷积核,会得到多个二维的输出结果,这些输出结果会被叠加在一起,得到一个三维的输出结果。这个结果传递给下一层。同时,对多个数据,即批处理,卷积层将多个样本汇总成一次处理,传递中综合成四维的数据。
池化层
池化层是一种降低数据大小的方法,它可以减少数据的大小,同时也可以防止过拟合。池化层的处理流程如下:
- 按照设定的步长,从输入数据中提取数据块
- 例如MAX池化,将数据块中的最大值作为输出结果
- 输出结果的规模即随步长变大而缩小
同时,池化层输入数据和输出数据的维度相同循环神经网络
循环神经网络常用于nlp领域。它和前馈神经网络或CNN的主要区别在于循环神经网络(RNN)的隐藏层的输出不仅仅取决于当前的输入,还取决于前一时刻的隐藏层的输出。因此,RNN具有某种程度上的“记忆”能力。
另一个显著特征在于它们在每个网络层共享参数,RNN在每一层都共享相同的参数,这使得它们可以处理任意长度的序列。
然而,RNN在反向传播的过程中,梯度会随着时间的推移而消失或爆炸,这使得它们很难学习长期依赖关系。注意力机制
注意力机制可以增强神经网络输入数据中某些部分的权重,同时减弱其他部分的权重。
例如对一个翻译句子的网络,普通的逐个词翻译会在每一轮翻译过程中对单词序列依次提高注意力,也就是其注意力矩阵会是一个对角线上权值高的矩阵。但是在注意力机制下,每一轮翻译过程中,网络会根据上一轮的翻译结果,对输入句子中的某些部分进行更多的关注,即其权值的最大值不一定在对角线。从而提高翻译的连贯性。并行计算
并行计算对计算任务进行拆分,将同时进行的计算任务分配到不同的计算单元上,从而提高计算速度。拆分的方式统称为并行方式,并行计算后的结果重新聚合的方式称为模型更新传递方式。
常见的并行方式有: - 数据并行:把数据集切分放到各个计算节点,并在哥哥节点之间传递模型参数
- 模型并行:把模型切分放到各个计算节点,并在各个节点之间传递数据。一般把单个算子分配在配置相同的几个硬件上进行模型存储和计算。
- 流水线并行:将模型切分成多个阶段,每个阶段在不同的计算节点上进行计算,每个阶段的计算结果传递给下一个阶段。
另外,如何更新模型参数也是并行计算的一个重要问题。在硬件组织架构方面,分为参数服务器架构和collective架构。在更新参数方面分为同步和异步更新参考内容allreduce训练
在同步更新参数的训练中,利用AllReduce来整合不同worker的梯度数据。AllReduce有很多种类的实现,主要关注的问题在于不同worker之间传递信息的拓扑结构。例如,对于一个有4个worker的集群,有以下几种拓扑结构: - ring:每个worker只和相邻的worker通信
- mesh:每个worker和所有其他worker通信,但是效率比较低。
- Master-Worker:一个worker作为master,其他worker作为worker,master和每个worker通信,worker之间不通信。
举N个worker的ring结构为例,考察这个结构的工作过程: - 每个worker计算自己的梯度
- 每个worker把数据分成N份
- 第k个worker把其第k份数据发送给第k+1个worker
- 第k个worker把其第k-1份数据和第k-1个worker发送的数据整合,再发给下一个worker
- 循环N次之后,每个worker包含最终整合结果的1份
- 每个worker把自己的数据发送给下一个worker,收到数据后,每个worker的数据都是最终整合结果
这个结构的AllReduce的优势在于发送的数据量是固定的,和worker数量无关,避免了网络拥塞。参考内容实践内容
lenet5
lenet5是进行手写数字识别的CNN,它的结构如下:
输入层->卷积层->池化层->卷积层->池化层->全连接层->全连接层->输出层(高斯连接)
与CNN不同的地方在于,LeNet使用sigmoid函数而非reLU函数。
lenet5网络的实现代码如下:这个网络定义了两个部分,一个是卷积层,一个是全连接层。卷积层的输入是一个1通道的图像,输出是一个6通道的图像,卷积核的大小为5*5。全连接层的输入是16*4*4的数据,输出是10个类别的概率。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return outputresnet
ResNet主要用于解决深度神经网络无法找到更好的解的问题。在深层网络中,梯度消失或爆炸的问题会导致网络无法训练。ResNet通过引入残差块(residual block)来解决这个问题。ResNet将堆叠的几个隐含层作为一个残差块,用残差块拟合的函数从原本的f(x)变为f(x)+x。
[4] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016:770-778.
通过每个block中残差路径和shortcut路径的设计,可以实现不同的ResNet网络。事实证明,不断增加ResNet的深度,也没有发生解的退化,反而可以提高网络的性能。因此ResNet可以实现如下的网络结构: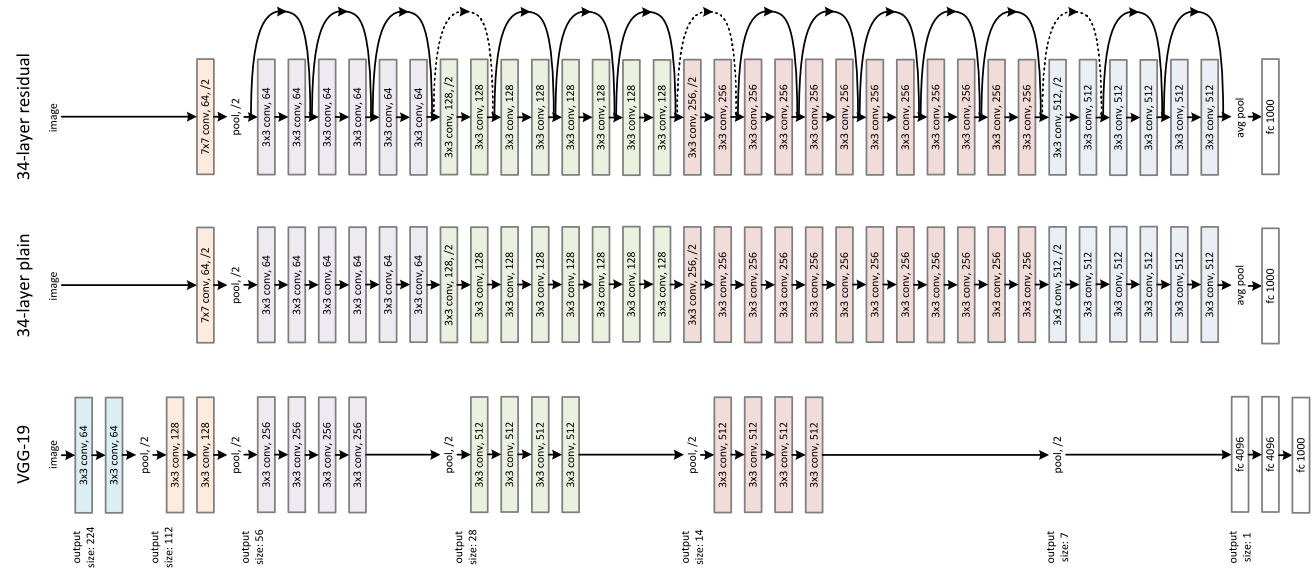
实际部署
残差块类定义如下:ResNet网络定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Bottleneck(nn.Module):
# 残差块定义
extention = 4
def __init__(self, inplanes, planes, stride, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.extention, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.extention)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride在30Epoch后,在测试集的准确度达到了75%。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class ResNet50(nn.Module):
def __init__(self, block, layers, num_class):
self.inplane = 64
super(ResNet50, self).__init__()
self.block = block
self.layers = layers
self.conv1 = nn.Conv2d(3, self.inplane, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplane)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.stage1 = self.make_layer(self.block, 64, layers[0], stride=1)
self.stage2 = self.make_layer(self.block, 128, layers[1], stride=2)
self.stage3 = self.make_layer(self.block, 256, layers[2], stride=2)
self.stage4 = self.make_layer(self.block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.extention, num_class)
BERT
BERT是基于Transformer的预训练模型,主要用于自然语言处理,它能够预测句子中缺失的词语。以及判断两个句子是不是上下句。
整个框架由多层transformer的encoder堆叠而成。encoder由注意力层和feed-forward层组成。
BERT中,输入由三种不同embedding组成:
wordpiece embedding:由但词向量组成将单词划分成一组有限公共子词单元。
position embedaang:将单词的位置信息编码成特征向量。Transformer通过制定规则来构建一个position embedding
segment embedding:用于区分两个句子的向量表示。用于区别问答等非对称子句。
网络结构
BERT的主要结构是Transformer,Transformer结构如下图所示:
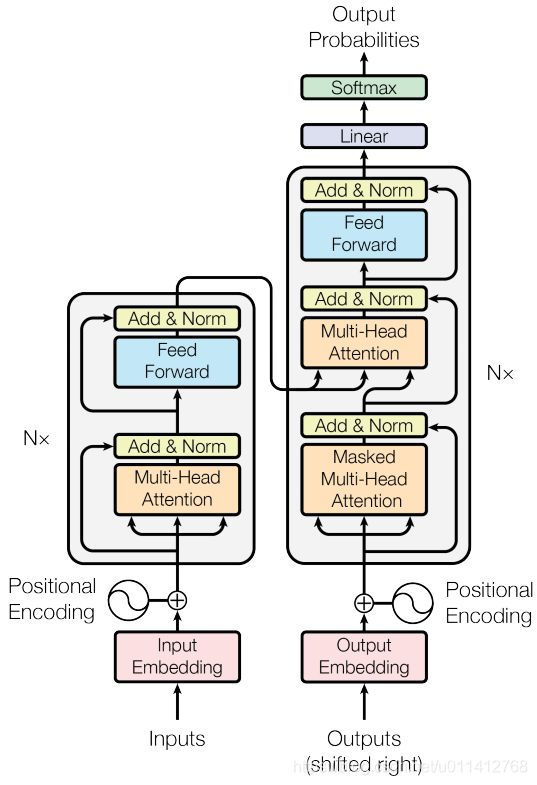
其中左侧部分即为encoder部分。
encoder单元由一个multi-head-Attention + Layer Normalization + feedforword + Layer Normalization 叠加产生。
在比较大的BERT模型中,有24层encoder,每层有16个Attention,词向量维度1024。在较小情况下,有12层encoder,每层12个Attention,词向量维度768。
任何时候feed-forward大小都是词向量维度的4倍。Attention Layer
这一层的输入是由X = (batch_size,max_len_embedding)构成的。
单个self-attention 计算过程是输入X分别和三个矩阵Wq,Wk,Wv相乘,得到Q,K,V。然后计算Q和K的点积,再除以$\sqrt{d_k}$,再经过softmax函数,得到attention矩阵。最后将attention矩阵和V相乘即加权求和,得到输出。
multi-head-Attention将多个不同的self-attention输出进行拼接,然后再乘以一个矩阵W0,得到最终的输出output_sum = (batch_size,max_len,n*w_length)这个结果再经过一个全连接层就是整个multi-head-Attention的输出。Layer Normalization
这个层相当于对每句话的embedding做归一化,所以用LN而非Batch Normalization
BERT每一层的学习
从浅层到深层分别可以学习到surface,短语,语法和语义的信息。
BERT的训练
定义几个层的类如下:
Embedding:输入的embedding层,包括wordpiece embedding,position embedding,segment embedding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Embeddings(nn.Module):
def __init__(self):
super(Embeddings, self).__init__()
self.seg_emb = nn.Embedding(n_segs, d_model)
self.word_emb = nn.Embedding(max_vocab, d_model)
self.pos_emb = nn.Embedding(max_len, d_model)
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(p_dropout)
def forward(self, x, seg):
'''
x: [batch, seq_len]
'''
word_enc = self.word_emb(x)
# positional embedding
pos = torch.arange(x.shape[1], dtype=torch.long, device=device)
pos = pos.unsqueeze(0).expand_as(x)
pos_enc = self.pos_emb(pos)
seg_enc = self.seg_emb(seg)
x = self.norm(word_enc + pos_enc + seg_enc)
return self.dropout(x)
# return: [batch, seq_len, d_model]Multi-Head-Attention层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2) / msqrt(d_k))
# scores: [batch, n_heads, seq_len, seq_len]
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
# context: [batch, n_heads, seq_len, d_v]
context = torch.matmul(attn, V)
return context
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, Q, K, V, attn_mask):
'''
Q, K, V: [batch, seq_len, d_model]
attn_mask: [batch, seq_len, seq_len]
'''
batch = Q.size(0)
'''
split Q, K, V to per head formula: [batch, seq_len, n_heads, d_k]
Convenient for matrix multiply opearation later
q, k, v: [batch, n_heads, seq_len, d_k / d_v]
'''
per_Q = self.W_Q(Q).view(batch, -1, n_heads, d_k).transpose(1, 2)
per_K = self.W_K(K).view(batch, -1, n_heads, d_k).transpose(1, 2)
per_V = self.W_V(V).view(batch, -1, n_heads, d_v).transpose(1, 2)
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# context: [batch, n_heads, seq_len, d_v]
context = ScaledDotProductAttention()(per_Q, per_K, per_V, attn_mask)
context = context.transpose(1, 2).contiguous().view(
batch, -1, n_heads * d_v)
# output: [batch, seq_len, d_model]
output = self.fc(context)
return output其余层,包括FeedForword层和池化层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class FeedForwardNetwork(nn.Module):
def __init__(self):
super(FeedForwardNetwork, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p_dropout)
self.gelu = gelu
def forward(self, x):
x = self.fc1(x)
x = self.dropout(x)
x = self.gelu(x)
x = self.fc2(x)
return x
class Pooler(nn.Module):
def __init__(self):
super(Pooler, self).__init__()
self.fc = nn.Linear(d_model, d_model)
self.tanh = nn.Tanh()
def forward(self, x):
'''
x: [batch, d_model] (first place output)
'''
x = self.fc(x)
x = self.tanh(x)
return xEncoder层和组合而成的BERT网络
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.enc_attn = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, x, pad_mask):
'''
pre-norm
see more detail in https://openreview.net/pdf?id=B1x8anVFPr
x: [batch, seq_len, d_model]
'''
residual = x
x = self.norm1(x)
x = self.enc_attn(x, x, x, pad_mask) + residual
residual = x
x = self.norm2(x)
x = self.ffn(x)
return x + residual
class BERT(nn.Module):
def __init__(self, n_layers):
super(BERT, self).__init__()
self.embedding = Embeddings()
self.encoders = nn.ModuleList([
EncoderLayer() for _ in range(n_layers)
])
self.pooler = Pooler()
self.next_cls = nn.Linear(d_model, 2)
self.gelu = gelu
shared_weight = self.pooler.fc.weight
self.fc = nn.Linear(d_model, d_model)
self.fc.weight = shared_weight
shared_weight = self.embedding.word_emb.weight
self.word_classifier = nn.Linear(d_model, max_vocab, bias=False)
self.word_classifier.weight = shared_weight
def forward(self, tokens, segments, masked_pos):
output = self.embedding(tokens, segments)
enc_self_pad_mask = get_pad_mask(tokens)
for layer in self.encoders:
output = layer(output, enc_self_pad_mask)
# output: [batch, max_len, d_model]
# NSP Task
hidden_pool = self.pooler(output[:, 0])
logits_cls = self.next_cls(hidden_pool)
# Masked Language Model Task
# masked_pos: [batch, max_pred] -> [batch, max_pred, d_model]
masked_pos = masked_pos.unsqueeze(-1).expand(-1, -1, d_model)
# h_masked: [batch, max_pred, d_model]
h_masked = torch.gather(output, dim=1, index=masked_pos)
h_masked = self.gelu(self.fc(h_masked))
logits_lm = self.word_classifier(h_masked)
# logits_lm: [batch, max_pred, max_vocab]
# logits_cls: [batch, 2]
return logits_cls, logits_lmbatch-size设为6
训练300个Epoch
训练结果进行预测例句
结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13========================================================
Masked data:
['[CLS]', '[MASK]', '[MASK]', 'you', 'too', 'how', 'are', 'you', 'today', '[SEP]', 'great',
'my', 'baseball', 'team', 'won', 'the', 'competition', '[SEP]']
BERT reconstructed:
['[CLS]', 'nice', 'meet', 'you', 'too', 'how', 'are', 'you', 'today', '[SEP]', 'great',
'my', 'baseball', 'team', 'won', 'the', 'competition', '[SEP]']
Original sentence:
['[CLS]', 'nice', 'meet', 'you', 'too', 'how', 'are', 'you', 'today', '[SEP]', 'great',
'my', 'baseball', 'team', 'won', 'the', 'competition', '[SEP]']
===============Next Sentence Prediction===============
Two sentences are continuous? True
BERT predict: True
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!